
数据库系统
数据库
参考https://superpung.notion.site/6c01057bb5c4474d9849b9df8e759bc1
2025.6.19
呜呜呜考的好烂😫下次一定好好复习)索引查询代价一定要看
关系数据模型
数据库是长期存储在计算机内,有组织的,可共享的数据的集合
DBMS是用户与操作系统之间的一层数据管理软件
事务处理的ACID性质:原子性,一致性,独立性,持久性
sql基本语法:
创建数据库:CREATE DATABASE 数据库名;
删除数据库:DROP DATABASE 数据库名;
一个数据模型包括结构,操作,约束三部分
Schema:关系(属性) ex:Movies(title,year,genre)
Tuple:关系的一行,包括每个属性 ex: (star,1979,comedy)
Domain: 与关系的每个属性相关 ex: Movies(title:string,year:integer,genre:string)
关系的键Key
表声明:
CREATE TABLE movieexec (
name CHAR(30),
address VARCHAR(255),
cert INT PRIMARY KEY, // 主键
networth INT,
FOREIGN KEY (attributeName) REFERENCES tableName(attributeName) // 外键,参照完整性
PRIMARY KEY (), // 实体完整性
);
sql数据类型:
CHAR(n) 长度为n的定长字符串
VARCHAR(n) 最大长度为n的变长字符串
INT 长整数
REAL 浮点数
BIT(n) 固定长度位串
BIT VARYING(n) 可变长度位串
DECIMAL(n,d)
DATE
TIME
实体完整性要求关系表的主键(Primary Key)不能为空值(NULL),而且每一行的主键值必须唯一。
定义:参照完整性约束用于维护外键(Foreign Key)与主键之间的依赖关系,要求外键的值要么为 NULL,要么必须对应主键表中的某个已有值。
插入数据:INSERT INTO 表名 VALUES ( );
查询:
1 | SELECT [ALL | DISTINCT] <目标列(属性)表达式>[, <目标列表达式>...] |
order by排序 ORDER BY 列名 [ASC|DESC];
group by对查询结果进行分组,HAVING 是对分组之后的结果筛选,在 SQL 中使用 GROUP BY 时,SELECT 子句中除聚合函数外的字段,必须全部出现在 GROUP BY 后面,这是为了保证分组后的查询结果是逻辑一致且可计算的。
修改关系模式
DROP TABLE R;
ALTER TABLE tableName ADD attributeName TYPE(n);(添加属性)ALTER TABLE tableName DROP attributeName;(删除属性)ALTER TABLE tableName ADD attributeName TYPE(n) DEFAULT ‘defaultValue’;(添加有默认值的属性)
default values 默认值
`ALTER TABLE tableName ADD attributeName TYPE(n) DEFAULT ‘haha’;
关系数据库语言
关系代数
Set operations : Union,Intersection, Difference
SELECT * FROM R UNION SELECT * FROM S;
SELECT * FROM R INTERSECT SELECT * FROM S;
SELECT * FROM R EXCEPT SELECT * FROM S;
Projection 投影 选择关系中的几个属性
SELECT [DISTINCT] genre FROM movies;
Selection选择 选择符合条件的关系
SELECT * from movies where length>100;
Cartesian Product笛卡尔积 RxS
SELECT * FROM R CROSS JOIN S;或SELECT * FROM R,S;
Natural join自然连接R\Join S 等价于从二者的笛卡尔积中选择出属性值相同的元组,再投影出属性集相并后的关系
SELECT * FROM U NATURAL INNER JOIN V;
Theta-join theta连接 等价于从二者的笛卡尔积中选择出一定条件的元组
SELECT * FROM U INNER JOIN V ON a>d;
重命名 rename \rho 将R的属性重命名为S的
Division 除法 找出所有在 R 中,对 S 中所有 B 都有关联的 A。
仅有的冗余:
- 交 = 差差
- Theta 连接 = 笛卡尔积的选择
- 自然连接 = Theta 连接的投影
LIKE模糊匹配字符串,%匹配任意长度的任意字符(包括 0 个),_匹配任意一个字符
NULL的规定:
- 任何数与NULL运算结果都是NULL
- 任何数与NULL比较结果都是UNKNOWN
- IS NULL操作
TRUE表示1,FALSE表示0,UNKOWN表示1/2
Subquery子查询
子查询是另一个查询的一部分,子查询可以嵌套
SELECT name FROM MovieExec WHERE cert = (SELECT * FROM Movies WHERE title = ‘Star Wars’);
SQL operators
s IN R
s > ALL R
s< ANY R
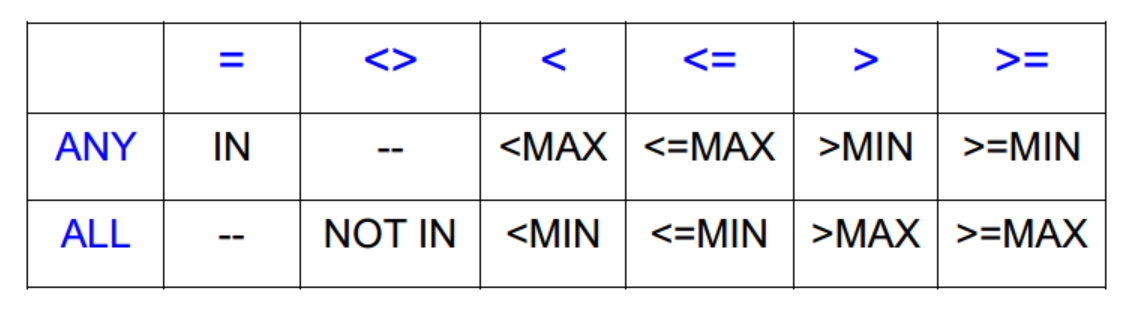
聚合函数 COUNT,SUM,AVG,MAX,MIN
Modification
INSERT INTO R(A1, …, An) VALUES (v1, …, vn);
DELETE FROM R WHERE 条件;
UPDATE R SET 新值 WHERE 条件
关系数据库设计理论
函数依赖FD
用于描述表中属性(列)之间的逻辑关系,对理解范式(如第三范式)和规范化非常重要。
在关系 R 中,若对于任意两个元组(行) t1 和 t2:
如果 t1[A] = t2[A],那么必有 t1[B] = t2[B],
就说 属性集 A 函数决定属性集 B,记作A->B
R 满足函数依赖 F:
- 确定关系 R 的每个实例都能使一个给定的 FD F 为真
- 作用:在 R 上声明了一个约束,而不是仅针对 R 的一个实例
关系的键:一组属性决定了该关系的其他所有属性,键是最小集合
有时一个关系可能会有多个键,通常需要指定其中一个为主键primary key
超键Superkey:一个包含键的属性的集合
等价 Equivalent:如果满足 FD S 的关系实例的集合和满足 FD T 的关系实例的集合相同,则 S 和 T 等价
推断 Follows:如果满足 FD T 的所有关系实例也满足 FD S,则 T 可以推断出 S(S follows from T)
规则:
- 分解规则 Splitting rule:A1A2…An → B1B2…Bm 等价于 A1A2…An → Bi,i = 1,2,…,m
- 组合规则 Combining rule:A1A2…An → Bi,i = 1,2,…,m 等价于 A1A2…An → B1B2…Bm
- 注意:左侧不能分解
平凡函数依赖:关系上的一个约束对所有关系实例都成立,且与其他约束无关,则这个约束就是平凡的,一个属性集可以函数决定它的子集

候选键是指:能唯一标识元组(记录),并且没有冗余的属性集合,能推出其他所有属性
计算属性的闭包
X+=在依赖集 F 中,所有能由 X 推导出的属性集合
计算方法:
- 初始化:令 X+:=XX^+ := XX+:=X
- 重复以下步骤直到不再变化:对于依赖 Y→Z∈FY \to Z \in FY→Z∈F,如果 Y⊆X+Y \subseteq X^+Y⊆X+,则将 ZZZ 加入 X+X^+X+
传递规则:属性集 A 函数决定属性集 B,属性集 B 函数决定属性集 C,则属性集 A 函数决定属性集 C
最小基本集:它是函数依赖集的一个等价表示,但去除了冗余,更便于分析候选键、范式分解等
- 最小基本集中所有 FD 右侧只有一个属性
- 从最小基本集中删除任何一个 FD,它不再是基本集
- 删除其中一个 FD 左侧的一个或多个属性,它不再是基本集
ArmStrong公理:用于推导出所有隐含的函数依赖
1.自反性:如果 Y⊆X,则 X→Y
2.增广性:如果 X→Y,则 XZ→YZ
3.传递性:如果 X→Y,Y→Z,则 X→Z
函数依赖集的投影:在一个关系 R 上存在一个函数依赖集 F,如果我们从 R 投影出一个子关系 S(属性子集),那么我们要找出在这个 S 上仍然成立的那些函数依赖

范式
为了解决数据库设计不规范造成的冗余,更新异常,删除异常
分解关系:
分解 Decomposition:给定关系 R(A1,A2,…,An),分解为 S(B1,B2,…Bm) 和 T(C1,C2,…,Ck) 满足:
- {A1,A2,…An} = {B1,B2,…,Bm} $\cup$ {C1,C2,…,Ck}
- $S = \pi_{B_1,B_2,…,B_m}(R)$
- $T = \pi_{C_1,C_2,…,C_k}(R)$
BC 范式 Boyce-Codd Normal Form,BCNF:每个非平凡FD的左侧必须是R的超键或者没有非平凡FD
任意一个二元关系都属于 BCNF
如何把关系分解为BCNF:
找到违反 BCNF 的依赖 X → A(X 不是候选键)
分解原关系 R 为两个关系:
- 一个关系:
X ∪ A - 另一个关系:
R - A(但保留 X)
重复以上过程,直到所有子关系都满足 BCNF
一道例题:https://blog.csdn.net/weixin_69884785/article/details/131377341
好的分解:
- 消除异常
- 可恢复信息
- 保持依赖
Lossless join无损连接
依照上述 BCNF 分解算法分解关系,则可以通过自然连接得到初始关系:
- 属性集 X、Y、Z
- 如果 R 有 FD Y → Z,且 R 的属性集为 $X\cup Y\cup Z$
- 则 $R = \pi_{X\cup Y}(R)\Join\pi_{Y\cup Z}(R)$
无损连接的chase检验
假设关系 R 的属性为 {A, B, C, …},分解成子关系 R₁, R₂, …,我们用一个表格模拟元组,跟踪属性值的变换
https://blog.csdn.net/weixin_56462041/article/details/130225013
dependancy preservation保持依赖
BCNF 分解后的关系,无法同时具有无损连接和依赖保持的性质
第三范式:
- 对于每个非平凡 FD A1A2…An → B1B2…Bm,要么属性集 A 是超键,要么 B - A 是主属性
- 对于每个非平凡 FD,或者其左侧是超键,或者其右侧仅由主属性构成,主属性是键的成员,无传递依赖
3NF分解步骤
第一步:为每个函数依赖创建关系模式
- R₁(A,B,C,D) —— 由AB→CD
- R₂(A,E) —— 由A→E
- R₃(B,F,H) —— 由B→FH
- R₄(C,G) —— 由C→G
- R₅(D,B) —— 由D→B
- R₆(G,C) —— 由G→C
- R₇(H,I) —— 由H→I
第二步:合并相同左部的关系
合并R₄和R₆(都基于C和G):
- R₄’(C,G) —— 合并C→G和G→C
第三步:检查候选键是否被包含
候选键是AB,已包含在R₁中
第四步:最终3NF分解
- R₁(A,B,C,D) —— {AB→CD}
- R₂(A,E) —— {A→E}
- R₃(B,F,H) —— {B→F, B→H}
- R₄’(C,G) —— {C→G, G→C}
- R₅(D,B) —— {D→B}
- R₇(H,I) —— {H→I}
验证无损连接性
使用Chase算法验证:
初始表:
Copy
Download
1
2
3
4
5
6R₁: A B C D a e1 f1 g1 h1 i1
R₂: A a B1 C1 D1 E a f1 g1 h1 i1
R₃: A1 B a C1 D1 E1 F a H a I1
R₄': A1 B1 C a D1 E1 F1 G a H1 I1
R₅: A1 B a C1 D a E1 F1 G1 H1 I1
R₇: A1 B1 C1 D1 E1 F1 G1 H a I a通过应用函数依赖可以推导出所有属性都有”a”,证明分解是无损的
验证依赖保持性
检查原始F中的每个依赖:
- AB→CD:由R₁保持
- A→E:由R₂保持
- B→FH:由R₃保持
- C→G:由R₄’保持
- D→B:由R₅保持
- G→C:由R₄’保持
- H→I:由R₇保持
所有依赖都被保持
最终3NF分解结果
ρ = {
R₁(A,B,C,D),
R₂(A,E),
R₃(B,F,H),
R₄’(C,G),
R₅(D,B),
R₇(H,I)
}
第一范式 First Normal Form,1NF:每个属性的值是原子值、有键。
第二范式 Second Normal Form,2NF:所有非主属性都被主键函数决定,不能被主键的一部分决定。
多值依赖MVD
- 两个属性或属性集合相互独立的断言
- 广义的函数依赖
在固定 X 的值时,Y 的所有可能取值集合,与 R 中其他属性无关,则X->->Y
定义:
- MVD A1A2…An →→ B1B2…Bm 指 B 的值与 R 中不在 A 和 B 中的属性是独立的
- 对于 R 中每个在所有 A 属性上一致的元组对 t 和 u,能在 R 中找到满足下列条件的元组 v:
- 在 A 属性上的取值与 t 和 u 相同
- 在 B 属性上的取值与 t 相同
- 在 R 中不属于 A 和 B 的所有其他属性上的取值与 u 子相同
- (x, y, z):x →→ y、x →→ z,r 中存在 (a, b, c) 和 (a, d, e),则 r 中也存在 (a, b, e) 和 (a, d, c)
平凡MVD:A1A2…An →→ B1B2…Bm({B_1,B_2,…,B_m}\subseteq{A_1,A_2,…,A_m}
MVD满足传递规则,但不满足分解规则和组合规则
每个FD都是MVD
互补规则:如果 A1A2…An →→ B1B2…Bm 是关系 R 中的 MVD,则 R 也满足 A1A2…An →→ C1C2…Ck(C 是 R 中除 A 和 B 外的属性集)
4NF范式:对于每个非平凡 MVD A1A2…An →→ B1B2…Bm,{A1, A2, …, An} 都是超键
4NF分解算法:
1.初始化\rho={R}
2.如果\rho的所有模式Ri都满足4NF,转4
3.如果\rho中有一个关系模式S不是4NF,则S中一定有一个多值依赖X->->Y且X不包含S的超键,S-Y-X不等于空集,XY不等于S,令Z=S-X-Y,设S1=XZ,S2=S-Z,用分解{S1,S2}代替S,由于S1交S2=X,S1-S2=Z,所以有(S1交S2)->->(S1-S2),分解具有无损连接性,接2
4.分解结束
ER模型
entity-relationship model
数据库设计阶段:思考 → 高级设计 → 关系数据库模式 → 关系 DBMS
E/R图
Entity Sets 实体集:实体 entity 是某种抽象对象,相似实体的集合形成实体集,E/R 图中用矩形表示
Attributes属性:实体集中实体具有的属性,E/R图中用椭圆表示,主键加下划线
Relationship联系:多个实体集的连接,E/R图中用菱形表示
联系的度:联系实体集的数量
二元E/R联系的多样性:
- 一对一:R 既是 E 到 F 的多对一联系,又是 F 到 E 的多对一联系
- 一对多:F 到 E 是多对一联系,则 E 到 F 是一对多联系
- 多对一:E 中任一实体与 F 中至多一个实体联系
- 多对多:R 既不是 E 到 F 的多对一联系,又不是 F 到 E 的多对一联系
设计原则:忠实性,避免冗余,简单性
E/R模型的约束
键:每个实体集都必须有一个键,通常选择其中一个键为主键,用下划线标识
参照完整性:箭头表示从E到F的多对一关系,F中的实体必须存在
度约束:边上加数字,约束实体联系的数量
弱实体集:一个实体集键由另一个实体集的部分或全部属性构成,一些实体不能独立存在,弱实体集是指依赖于其他实体集的实体集合。它们没有自己的唯一标识符,只能通过与其相关联的其他实体集来进行识别和区分
弱实体集表示法:双边框的矩形,其多对一的关系显示为双边框的菱形
约束与触发器
约束
约束:数据库强制施加在表字段(列)上的规则,用来限制插入、更新或删除的数据必须符合某种要求
主键约束(PRIMARY KEY):主键 = NOT NULL + UNIQUE,唯一标识一行
外键约束(FOREIGN KEY):外键,引用另一个表的主键,保持参照完整性,被参照的属性必须是主键或 Unique
对于被引用表的值的修改,引用表有三种处理方式:
默认:拒绝修改
casecade:引用表作同样修改
Set NULL:把引用表的值改为NULL
唯一约束(UNIQUE):所有值必须唯一
非空约束(NOT NULL):不允许为NULL,外键更新的方案 1 不可行、Set NULL 策略不可行
声明外键时可以指定策略:属性后跟 ON [UPDATE, DELETE] [SET NULL, CASCADE]
CHECK:自定义条件约束
DEFAULT:指定默认值
1 | CREATE TABLE Student ( |
循环约束条件
延迟约束检查:在参照的属性中插入或更新值,这个值不在被参照的属性中,有三种解决方案:
- 先插入其他属性值,参照属性值置空,再在被参照的关系中插入新的元组包含值,最后更新参照的属性值(问题是参照的属性不能被其他属性参照,而且不能有非空约束)
- 先在被参照的关系中插入,再在参照的关系中插入(问题是两个关系不能存在循环约束)
- 循环约束 circular constraints:不能通过改变顺序解决,不能插入新值
- 延迟检查:将两个插入组成事务,告知 DBMS 直到整个事务完成要提交时再检查约束
延迟检查声明:外键后跟DEFERRABLE INITIALLY DEFERRED在每个事务提交之前检查
DEFERRABLE INITIALLY IMMEDIATE每条语句之后检查,与not deferrable相同,但是可以修改延迟状态
SET CONSTRAINTS myconstraint DEFERRED;
NOT DEFERRABLE(默认)数据库修改语句执行,立即检查约束
基于属性的check约束:属性后面跟check条件,presc INT, CHECK (presc IN (SELECT cert FROM movieExec))
基于元组的check约束:触发条件更强、更频繁,对元组的任意属性的修改都会触发
- 如果约束涉及元组的多个属性,则必须是基于元组的约束
- 如果约束仅涉及元组的一个属性,则二者都可
修改约束:
给约束命名:
CONSTRAINT 约束名 约束
修改约束:
SET CONSTRAINT 约束名 DEFERRED 或 IMMEDIATEALTER TABLE 关系名 DROP CONSTRAINT 约束名ALTER TABLE 关系名 ADD CONSTRAINT 约束名
断言:数据库模式的元组,像关系和视图一样
CREATE ASSERTION 断言名 CHECK 条件,条件可以引用数据库模式的任何关系或属性,断言是一个布尔值的 SQL 表达式,必须一直为真
删除:DROP ASSERTION 断言名
触发器
只有特定事件发生时才被激活
1 | CREATE TRIGGER 触发器名 |
- 行级触发器 row-level:一次只对一个元组
- 语句级触发器 statement-level:一次针对 SQL 语句中被改变的所有元组
视图和索引
视图
在表或其他视图上的查询所定义的一种关系,分为虚拟视图和物化视图(materialized )
声明:CREATE [MATERIALIZED] VIEW 视图名 AS 查询,默认为虚拟视图
可以像查询基本表一样查询视图。
有些时候可以对视图进行插入删除更新操作
删除:DROP VIEW 视图名
DROP TABLE 表名(视图不可用)
可更新视图
前提:
- 从一个基本表 R 中 SELECT 一些属性
- WHERE 子句在子查询中不能使用关系 R
- FROM 子句只能包含 R,不能有其他关系
- SELECT 足够多的属性
更新视图的影响:
- 视图中插入:在基本表中插入,视图中没有的属性用 NULL
- 视图中删除:从基本表中删除,须同时满足视图中删除的条件和定义视图的条件
- 视图中更新:在基本表中更新,须同时满足视图中更新的条件和定义视图的条件
视图中的触发器:在视图上定义触发器,用 INSTEAD OF,将那些对视图进行更改的操作,替换为在基本表上的合适的操作。
1 | CREATE TRIGGER para |
索引
index:用来加速访问关系中的元组的数据结构,提高在属性 A 上查找具有某个特定值的元组的效率,可以是哈希表,但在 DBMS 中是 B-树,一种广义上的平衡二叉树
声明:CREATE INDEX 索引名 ON 关系名(属性名),属性可以有多个,有顺序
删除:DROP INDEX 索引名
索引的选择
选择一组值创建索引,索引会使给关系的插入删除更新操作复杂耗时
最有效的索引是键的索引
物化视图:如果某个视图频繁使用,将它实体化效率更高
服务器和安全
三层体系结构
通用的体系结构:
- Web 服务器:连接客户端与数据库系统
- 应用服务器:执行交易逻辑
- 数据库服务器:运行 DBMS 并且执行应用服务器请求的查询和更新
PSM
持久性存储模块 PSM = 其他语句(if、while 等)和 SQL 的混合
1 | CREATE PROCEDURE <name> ( |
局部声明:DECLARE 变量名 类型 默认值
参数:模式-名称-类型三元组:
- 模式 mode:IN、OUT、INOUT
调用:CALL 存储过程名 (参数列表)
条件语句,循环语句等语法
cursor
用户授权
SQL 识别更详细的权限集,在关系上,一共 9 种:
SELECT [on relation | attributes list]查询的权限INSERT [on relation | attributes list]插入元组的权限DELETE删除元组的权限UPDATE [on relation | attributes list]更新元组的权限REFERENCE [on relation | attributes list]被约束引用的权限USAGE [模式元素 除了关系和断言]在自己的声明中使用这个元素的权限TRIGGER [on relation]在关系上定义触发器的权限EXECUTE执行代码的权限,例如 PSM 存储过程或函数UNDER在给定类型创建子类型的权限
授予权限:GRANT <权限列表>
ON <关系名或视图名>
TO <用户或角色列表>;
在默认方式下,被授予权限的用户/角色无权把得到的权限再授予给另外的用户/角色。
GRANT <权限列表>
ON <关系名或视图名>
TO <用户或角色列表>
WITH GRANT/ADMIN OPTION;
加上 WITH GRANT OPTION,表示被授权的用户可以把这个权限再授权给其他人。
收回权限:REVOKE <权限列表>
ON <关系名或视图名>
FROM <用户或角色列表>;
假如超级管理员U1授权给U2,U2又授权给U3,U3又授权给了U4,当U1要收回U2的授权时,U3和U4的授权也被收回。这种从一个用户/角色收回权限可能导致其他用户/角色也失去该权限,这一行为称作级联收回。
对于使用with admin option授予权限的用户,系统收回其权限时,不会级联收回。
CASCADE:收回权限时也要收回那些仅仅由于要收回权限而被授予的权限RESTRICT:如果权限被传递给其他人,收权语句不执行
授权图
AP表示授权ID A有权限P,AP*表示有授权选项,AP**表示A是权限P的属主
当 A 授权 P 给 B,则在 AP* 或 AP** 到 BP 间画一条边(如果有授权选项,则是 BP*)
基本规则:用户 C 有权限 Q,只要从 XP** 到 CQ/CQ*/CQ** 有边,且 P 是 Q 的父权限。(P 可能是 Q,X 可能是 C)
A 级联收回 B 的 P 权限,则删除从 AP 到 BP 的边。
A RESTRICT 收回 B 的 P 权限,且 BP 有出发的边,则拒绝收权,无事发生。
数据库恢复
事务
显式定义:
BEGIN TRANSACTION 语句 COMMIT:提交,事务正常结束BEGIN TRANSACTION 语句 ROLLBACK:回滚到事务开始时状态,事务非正常结束
隐式定义:
- 每一个查询或更新语句都是一个事务
提交 COMMIT:
- 事务完成
- 数据库更新将永久保存
回滚 ROLLBACK:
- 事务 abort
- 对数据库没有影响
- 举例:除以 0、违反约束
原语操作:
x 是数据库元素
- INPUT(x):将包含 x 的磁盘块拷贝到内存缓冲区
- OUTPUT(x):将包含 x 的缓冲区拷贝回磁盘
- READ(x,t):将内存缓冲区的 x 拷贝到事务的局部变量 t
- WRITE(x,t):将局部变量 t 的值拷贝到内存缓冲区的 x
undo logging
保证事务原子性(整体被执行/不执行)的一种方法
在系统故障之前,通过撤销可能未完成的事务的影响来修复数据库状态
仅更新记录<T,X,v>
事务T更改了数据库元素X,更改前的值为v
更新记录所反映的改变通常发生在主存中而不是磁盘上,即日志记录是对 WRITE 做出的反应,而不是对 OUTPUT 做出的反应
undo-logging rules:
- U1:如果事务 T 改变了数据库元素 X,那么形如 <T, X, *v*> 的日志记录必须在 X 的新值写到磁盘前写到磁盘
- U2:如果事务提交,则其 COMMIT 日志记录必须在事务改变的所有数据库元素已写到磁盘后再写到磁盘,但应尽快
必须按照以下顺序写入磁盘:
1.显示数据库元素发生变化的日志记录
2.变更后的元素本身
3.提交日志记录
为了强制将日志记录写到磁盘,日志记录需要一条刷新日志命令,告诉缓冲区管理器:将以前没有拷贝到磁盘的日志记录、从上一次拷贝以来已发生修改的日志记录拷贝到磁盘,FLUSH LOG
事务管理器需要告诉缓冲区管理器:在某个数据库元素上执行 OUTPUT 动作
redo logging
在事务修改数据后,将新值写入日志
延迟修改:数据修改后暂存内存,提交后批量写入磁盘
写入磁盘顺序:日志->COMMIT->数据
undo/redo:同时记录旧值和新值
数据库恢复机制
undo/redo模型
| 类型 | 含义 |
|---|---|
| Redo 所有已提交事务(COMMIT) | 即使数据页已在内存或磁盘中,也要重做已提交事务的操作,确保持久性。 |
| Undo 所有未提交事务 | 撤销所有未提交事务对数据库的修改(从日志中恢复“旧值”) |
恢复操作:日志回放,倒序扫描
追加日志:<UNDO T1, B, 21, 20>
<UNDO T1, D, 41, 40>
并发控制

两个操作属于冲突操作,必须满足:
- 它们作用于同一数据项;
- 它们至少一个是写操作;
- 它们属于不同的事务
| 概念 | 一句话定义 | 区别 |
|---|---|---|
| 可串行化 | 一个调度如果等价于某个串行执行的调度,就是可串行化。 | 强调效果一样 |
| 冲突可串行化 | 如果一个调度通过交换不冲突的操作可以变成某个串行调度,就是冲突可串行化。 | 强调操作顺序一样 |
冲突可串行化是可串行化的子集
优先关系图
检查一个调度是不是冲突可串行化的。
结点:调度的事务,标下标
边:Ti → Tj,指 Ti 优先于 Tj,写做 Ti < sTj,满足:
- Ti 的动作 A1、Tj 的动作 A2
- 调度 S 中 A1 在 A2 之前
- A1 和 A2 涉及同一数据库元素,且二者中至少一个是写
构建优先图,判断是否有环
二阶段锁协议要求:一个事务加锁和释放锁分为两个阶段,加完锁之后就不能再加锁,只能释放。
为什么二阶段锁有效?
如果只有加锁阶段(没解锁) ⇒ 死锁、资源不释放;
如果加锁和解锁随意交错 ⇒ 事务可以“插队”改变本应串行的顺序 ⇒ 出现并发异常(脏读、不可重复读等);
所以二阶段锁是实现串行化的恰好最小限制条件。
锁
共享锁(shared-lock):允许多个事务并发读取数据,不能修改数据
排他锁(exclusive lock):事务可以读写数据
更新锁(update lock):为了防止死锁设计,用于“读后写”的场景:先加更新锁,准备更新数据,等确认写时再升级为排他锁。
一个资源只能有一个更新锁,但与共享锁兼容。


